Keras之分类模型深度神经网络DNN+批归一化+激活函数selu+Dropout
深度神经网络DNN+批归一化+激活函数selu+Dropout
零.导入所需库
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
2.0.0-alpha0
sys.version_info(major=3, minor=6, micro=13, releaselevel='final', serial=0)
matplotlib 3.3.4
numpy 1.16.2
pandas 1.1.5
sklearn 0.24.1
tensorflow 2.0.0-alpha0
tensorflow.python.keras.api._v2.keras 2.2.4-tf
一.加载数据集,划分训练集,测试集,验证集
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
二.数据归一化
# x = (x - u) / std
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train: [None, 28, 28] -> [None, 784]
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
三.模型建立
# tf.keras.models.Sequential()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
# 使用selu激活函数代替relu
model.add(keras.layers.Dense(100, activation="selu"))
# 批归一化只需要在此处加上即可
model.add(keras.layers.BatchNormalization())
#在最后一层进行Dropout
model.add(keras.layers.AlphaDropout(rate=0.5))
# AlphaDropout: 1. 均值和方差不变 2. 归一化性质也不变
# model.add(keras.layers.Dropout(rate=0.5))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",
optimizer = "sgd",
metrics = ["accuracy"])model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 100) 78500
_________________________________________________________________
batch_normalization_v2 (Batc (None, 100) 400
_________________________________________________________________
dense_1 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_1 (Ba (None, 100) 400
_________________________________________________________________
dense_2 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_2 (Ba (None, 100) 400
_________________________________________________________________
dense_3 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_3 (Ba (None, 100) 400
_________________________________________________________________
dense_4 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_4 (Ba (None, 100) 400
_________________________________________________________________
dense_5 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_5 (Ba (None, 100) 400
_________________________________________________________________
dense_6 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_6 (Ba (None, 100) 400
_________________________________________________________________
dense_7 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_7 (Ba (None, 100) 400
_________________________________________________________________
dense_8 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_8 (Ba (None, 100) 400
_________________________________________________________________
dense_9 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_9 (Ba (None, 100) 400
_________________________________________________________________
dense_10 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_10 (B (None, 100) 400
_________________________________________________________________
dense_11 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_11 (B (None, 100) 400
_________________________________________________________________
dense_12 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_12 (B (None, 100) 400
_________________________________________________________________
dense_13 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_13 (B (None, 100) 400
_________________________________________________________________
dense_14 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_14 (B (None, 100) 400
_________________________________________________________________
dense_15 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_15 (B (None, 100) 400
_________________________________________________________________
dense_16 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_16 (B (None, 100) 400
_________________________________________________________________
dense_17 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_17 (B (None, 100) 400
_________________________________________________________________
dense_18 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_18 (B (None, 100) 400
_________________________________________________________________
dense_19 (Dense) (None, 100) 10100
_________________________________________________________________
batch_normalization_v2_19 (B (None, 100) 400
_________________________________________________________________
alpha_dropout (AlphaDropout) (None, 100) 0
_________________________________________________________________
dense_20 (Dense) (None, 10) 1010
=================================================================
Total params: 279,410
Trainable params: 275,410
Non-trainable params: 4,000
_________________________________________________________________
四.训练及回调保存权重
log_dir= os.path.join('logs-selu-dropout') #win10下的bug,
if not os.path.exists(log_dir):
os.mkdir(log_dir)
tensorboard = tf.keras.callbacks.TensorBoard(log_dir = log_dir)
EarlyStopping = keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
history = model.fit(x_train_scaled, y_train, epochs=10,
validation_data=(x_valid_scaled, y_valid),
callbacks = [tensorboard, EarlyStopping])
save_dir = './modelckpt/'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
model.save('modelckpt/mdoel-selu-dropout.h5')Train on 55000 samples, validate on 5000 samples
Epoch 1/10
55000/55000 [==============================] - 16s 286us/sample - loss: 1.5080 - accuracy: 0.5055 - val_loss: 0.7284 - val_accuracy: 0.7992
Epoch 2/10
55000/55000 [==============================] - 13s 227us/sample - loss: 0.9795 - accuracy: 0.6918 - val_loss: 0.7077 - val_accuracy: 0.8218
Epoch 3/10
55000/55000 [==============================] - 12s 225us/sample - loss: 0.8506 - accuracy: 0.7341 - val_loss: 0.6450 - val_accuracy: 0.8424
Epoch 4/10
55000/55000 [==============================] - 12s 226us/sample - loss: 0.7818 - accuracy: 0.7578 - val_loss: 0.6183 - val_accuracy: 0.8508
Epoch 5/10
55000/55000 [==============================] - 12s 225us/sample - loss: 0.7206 - accuracy: 0.7743 - val_loss: 0.6067 - val_accuracy: 0.8576
Epoch 6/10
55000/55000 [==============================] - 12s 226us/sample - loss: 0.6917 - accuracy: 0.7845 - val_loss: 0.5842 - val_accuracy: 0.8604
Epoch 7/10
55000/55000 [==============================] - 13s 235us/sample - loss: 0.6617 - accuracy: 0.7930 - val_loss: 0.5691 - val_accuracy: 0.8692
Epoch 8/10
55000/55000 [==============================] - 14s 259us/sample - loss: 0.6320 - accuracy: 0.8052 - val_loss: 0.5516 - val_accuracy: 0.8658
Epoch 9/10
55000/55000 [==============================] - 14s 258us/sample - loss: 0.6208 - accuracy: 0.8041 - val_loss: 0.5566 - val_accuracy: 0.8678
Epoch 10/10
55000/55000 [==============================] - 14s 258us/sample - loss: 0.5939 - accuracy: 0.8136 - val_loss: 0.5528 - val_accuracy: 0.8704
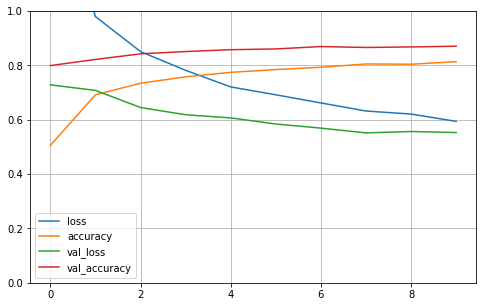
五.看下训练分布,验证分布
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
# 1. 参数众多,训练不充分
# 2. 梯度消失 -> 链式法则 -> 复合函数f(g(x))
# selu缓解梯度消失
model.evaluate(x_test_scaled, y_test)10000/10000 [==============================] - 1s 95us/sample - loss: 0.6243 - accuracy: 0.8568
[0.6242977780580521, 0.8568]
test_loss, test_acc = model.evaluate(x_test_scaled, y_test)
print("准确率: %.4f,共测试了%d张图片 " % (test_acc, len(x_test)))10000/10000 [==============================] - 1s 92us/sample - loss: 0.6243 - accuracy: 0.8568
准确率: 0.8568,共测试了10000张图片
# 随机验证结果
import random
randKey = random.randint(1, len(x_test_scaled))
y = model.predict(np.reshape(x_test_scaled[randKey], (1, 28, 28)))
print(y.flatten().tolist())
print('预测结果:' + str(np.argmax(y[0])))
print('实际结果:' + str(y_test[randKey]))[1.2241130775692e-08, 4.9439517368909947e-08, 6.662384866018556e-09, 1.1605064464959014e-08, 2.964944023631233e-08, 0.9999634027481079, 2.124420195315224e-09, 2.9575381631730124e-05, 2.498188678146107e-06, 4.46141348220408e-06]
预测结果:5
实际结果:5